In November of last year, I was invited to give a fairly informal talk on the
topic of my choice at Dropbox. I decided to go with the mildly controversial
topic of advocating Dropbox employees to consider making side businesses.
They were gracious enough to furnish me with a recording of the talk, which you
may also enjoy below. It’s got a few nuggets about how I think about running a
small business and some mistakes you probably want to avoid making.
If you’ve tried to make a Google Hangouts app, you probably already know that it
sucks pretty badly. Famously terrible documentation, crazy bloated
JavaScript, and mandated UX requirements. You also might know that you
can craft a URL to open a new hangout without any of the bloat like so:
https://plus.google.com/hangouts/_
But what if you want to make a hangout with your app and set its app_type to
ROOM_APP so that your app is loaded for everyone by default?
Well, some digging on the internet suggests that you can write a URL of the form
.../_/?gid=YOUR_GID&gd=INITIAL_DATA
to open a new hangout session with your app loaded and data passed to it.
Unfortunately, this does not set the app_type flag specified in Google’s
initial app parameters API. The only way to do so at this time appears to
be Google’s official platform.js API to render an
“Official G+ Hangouts Button”.
Fuck that.
There’s a bunch of reasons you might not want to play nice, but before going
further you should take note of the Google buttons policy. Yes, they have
an official policy on buttons. It’s a bit murky about whether you are allowed to
programatically generate links to create Hangouts sessions, but the thrust of
the policy is mostly about not misleading users and not snooping their data, so
I assume this is mostly fine.
Reverse Engineering the Hangouts Button
Google’s example for generating a hangouts button via the JS API is:
which then redirects to a normal hangouts URL where your app is embedded as a
full room app. Let’s break apart what’s going on here. The params in that URL
are:
hl seems obviously to be locale, and lb1 and hscid both seem to be
timestamp-related. A bit of experimentation proves that everything works as long
as ssc is included, so we can drop the rest of the params. But what is ssc?
It looks suspiciously like a Base 64 encoded blob, so we decode it:
This looks like a big serialized protobuf or something like it to me. Most of
the fields are unused, and even the obvious timestamp fields are unnecessary.
The following blob works just as well:
We’ve removed the timestamps and the magic number “92” (I have no idea what
it’s for). All that we have left is the app ID, the initial data, and “2” to
signify ROOM_APP. Erego, to create a URL to open a hangouts session to an
app with APP_ID, INITIAL_DATA as a ROOM_APP in Ruby:
The latest startup from internet luminary Max Levchin recently launched,
and they have a very entertaining programming puzzle up on their jobs page.
You should read the page for some background, but in summary the problem is to
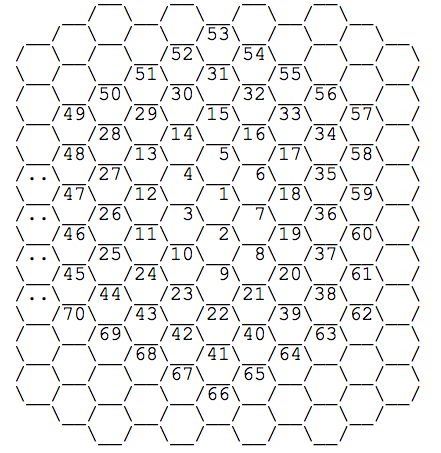
find the distances between any two cells in a hexagonal grid numbered in the
following manner:
Approach
The problem is interesting because the problem seems like a traditional graph
theory exercise, but Affirm hints that your solution should work at the scale of
ten billion nodes. These two ideas don’t really jive, so one wonders if there’s
an analytic solution that doesn’t involve any graph traversal.
It seems plausible that there is one, since the problem seems very similar to
calculating the Manhattan Distance between any two nodes in a rectangular
grid, except in this case we have a hexagonal grid where there are six ways to
move between neighboring nodes instead of four. These six neighboring cells lie
along three axes of movement.
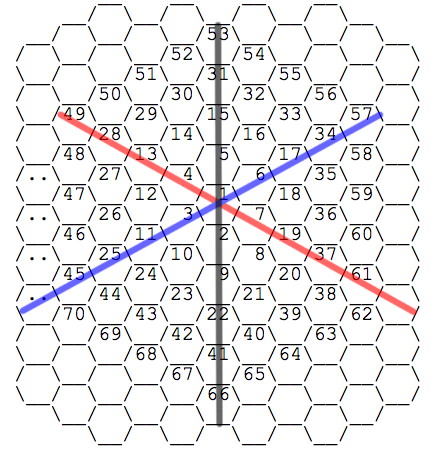
If you play around with the axes in your head, you can see that you can
represent any hexagon in terms of any two of the three axes of movement. The
corollary to that conclusion is that any translation down one axis of movement
can be thought of as some combination of the other two. Essentially, we have one
almost-unnecessary axis.
This suggests an approach:
Turn a hex’s number into its grid coordinates
Figure out the distance between two arbitrary grid coordinates
Translating a hexagon number into coordinates
Going from an arbitrary hexagon number to coordinates seems a bit tricky at
first. You can’t modulo or divide by anything obvious to get some aspect of the
geometry. The hex at position 1000 could be almost anywhere. What does seem
obvious, though, is that higher numbers must be on larger “rings” of hexagons.
Closer examination shows that each larger ring of hexagons has 6 more nodes than
the last. Therefore:
The formula seems to check out, since the 0^th ring ends in 1, the 1^st ring in
7, the 2^nd ring in 19, and so on. Programmatically, you could tell which ring a
hex falls on by finding which two “max-ring” numbers the hex is between. In the
case of say, 12, it would be the 2^nd ring, since it is greater than 7 and less
than 19. However, we can do better mathematically by simply inverting the
previous formula, to get one that takes a number and outputs a ring:
Plugging in num = 10 gets us a ring number of ~1.3, which we round up to 2.
Looks good! Now that we have the ring, we have to do the hard part: figure out
where exactly on the ring we are. It also means we need to finalize our axes.
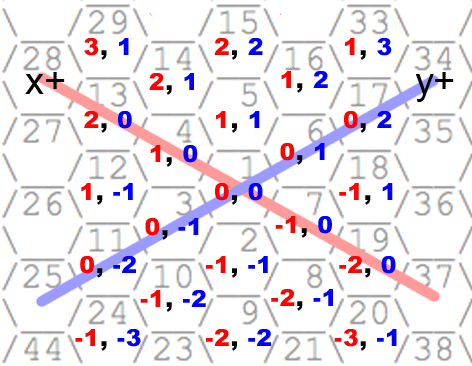
I’ve illustrated the coordinate system I went with below. Why I choose this
particular configuration should become clear later:
Following the pattern of coordinates here, you can see the largest number on
each ring occurs on the negative X axis. Essentially we can say that if a number
is the largest number on ring n, its position will be (0, -n). After a bit more
thought, I figured that you could represent the various corners of the unit
hexagon as six vectors that all pointed to hexagons exactly one away from the
origin, like so:
You can get any number’s position along its hexagon ring by figuring out which
of the six sides of the hexagon it is on, and its distance from the last corner
of the hexagon.
defring_to_max_numring3*ring**2+3*ring+1enddefnum_to_ringnum(Math.sqrt((4*num-1)/12.0)-0.5).ceilenddefnum_to_coordsnumreturnVector[0,0]ifnum==1# The length of a side is also the ring numberside_length=ring=num_to_ringnum# How far away am I from the end of my ring?offset=ring_to_max_num(ring)-numside_number=offset/side_lengthside_offset=offset%side_lengthcorner=UNIT_HEXAGON[side_number]# The direction to the next corner is just the position of the# next corner minus the position of the current one.direction=UNIT_HEXAGON[(side_number+1)%6]-corner(corner*ring)+(direction*side_offset)end
Solving for distance
So now we can easily get the grid coordinates of the start and end node. We
still have to solve for the distance between them. A quick observation shows
that the distance necessary to travel any delta vector is the same regardless of
starting and ending nodes. That is to say, moving (+3, +2) units is the same
distance whether you start at hex 1 or 1000. Luckily, with the axes I’ve chosen,
calculating this distance isn’t too hard. At any given hexagon, you can move one
unit along either the X or Y axes. You can also move one unit up or down the
third axis, which is equivalent to moving by either (+1, +1) or (-1, -1). Our
choice of axes has made that bit simple.
The process for finding the distance of a delta is:
If the coordinates of the delta share a sign (both positive or negative), the
distance is just the maximum of the absolute values of both coordinates. In
moving (+3, +5), for instance, you move first to (+3, +3) in three moves, and
then to (+3, +5) in another two for a total distance of five. The same is true
of (-3, -5), with reversed directions.
If they do not share a sign, merely add both of their absolute values
together. For instance, moving (+2, -6) takes eight moves, because you have to
move +2 in the X direction and -6 in the Y. Moving along the Z axis cannot aid
you here.
deflength_of_deltadeltadelta=-1*deltaifdelta.all?{|i|i<0}delta.all?{|i|i>0}?delta.max:delta.max-delta.minenddefdistance_betweennum1,num2delta=num_to_coords(num1)-num_to_coords(num2)length_of_deltadeltaendnum1=ARGV[0].to_inum2=ARGV[1].to_iputs"distance between #{num1} and #{num2} is #{distance_betweennum1,num2}"
And viola, a constant-time algorithm that works fine at 10 billion nodes:
~/misc/affirm $ time ruby honeycomb.rb 1 100
distance between 1 and 100 is 6
real 0m0.030s
user 0m0.023s
sys 0m0.005s
~/misc/affirm $ time ruby honeycomb.rb 1 10000000000
distance between 1 and 10000000000 is 57735
real 0m0.030s
user 0m0.024s
sys 0m0.005s
Extra Credit
Solving for distance was nice, but honestly a bit anticlimactic. Wouldn’t it be
more impressive if we could actually output the number of each hexagon on the
way to our destination?
This function constructs a path of coordinates from pos1 to pos2, by attempting
to move one hex at a time, favoring the Z axis where possible and otherwise just
moving down the X or Y axes if there exists a remaining delta on either axis.
However, we still only have a path in coordinates. To get back to hexagon
numbers, we need a translation function. This article is getting a bit long, so
I’ll just leave it here as an exercise for the reader to puzzle out:
~/misc/affirm $ ruby ../misc/affirm/honeycomb.rb 1 100
distance between 1 and 100 is 6
path is [1, 2, 9, 22, 42, 68, 100]
Magic! The runtime here is $O(\sqrt{n})$, because the path-finding algorithm is
linear on the length of the path, and the path can only be as long as the square
root of the largest hexagon number on the path. Recall that the ring of a
hexagon number is a function of the square root of that number.
Posit that humans are just the reproductive organs of ideas, and our minds
little more than churning pools of interchanging notions. In short, standard
meme theory. We might be hosts whose carefully formulated egos are nothing
more than the emergent terrain of an ancient memetic battleground - one imagines
long wars between the myriad incarnations of fear and laziness for control of
our weary brains. The memes with the most dominant survival characteristics must
have long since evolved - likely candidates being caution, hope, and solidarity.
In this paradigm, the most prolific ideas are the hardiest survivors of
thousands of years of crossbreeding, their properties now the building blocks of
more complicated and fragile abstractions like justice, ambition, and
melancholy. The simplest ideas might occupy the lowest and most important rungs
of an intellectual ecosystem, akin to our humble meat-space phytoplankton.
However, how do ideas like self-destruction and asocialism breed, if their
character makes their owners shun reproducing? The answer may lie in the non-
intuitive fact that the reproduction of ideas need not be necessarily coupled
with the reproduction of humans. Have you found yourself slighted when cut off
on the highway, and thus spurred to cut another off in the same way? Some ideas
may predispose their hosts towards not mating, and yet be potent enough to
spread from individual to individual. Biologists have even identified similar
processes in the field, where individual bacteria swap genetic material without
reproducing. They call this act Horizontal Gene Transfer, and it may be a
more widely applicable concept than they know.
More broadly, the reproduction criteria for a meme have little to do with the
host at all, beyond causing the host to express behaviors that cause others to
adopt that same meme. In Biology, in order for a lethal virus to survive, it
must assure that its genetic code is passed on before it destroys its host. This
seemingly ironclad Darwinian rule of the natural world need not apply to the
spread of ideas. Consider again that for ideas to be exchanged, humans do not
even have to meet face to face, or even be alive simultaneously. How many
suicides were born decades before they occurred, spread posthumously by another
carrier, like an oak desperately dropping acorns in the death throes of a fire.
The striking tragedy of a suicide is more than just sadness, but the idea’s
resilience in the minds of its witnesses. The kernel of the idea sits idly for
years in the intellectual field of a man’s mind until the fire of anger or
loneliness causes the undergrowth to clear enough for the seed of suicide to
sprout. Perhaps I erred, then, in suggesting that the most popular memes are
hardier than their less successful cousins.
What is the nature of our relationship with ideas? In some cases it seems
parasitic, especially with self-destructive ideas. The will to self-destruct
manifests itself at great personal cost to its host. Other ideas seem symbiotic,
like tribalism and love. Through expressing themselves in us, these ideas not
only heighten their own odds at survival, but bring us happiness and safety as
well. Still others seem hard to classify, like asceticism and other highly
abstract pursuits. It seems evident that humans and ideas need each other to
survive, but beyond that, their relationship is murky.
Perhaps the binary of parasitism and symbiosis is unhelpful. What if ideas owe
each other more allegiance than they owe us, and vice versa? We readily accept
the notion that the wolves who prey on the slowest of deer place a selection
pressure on the herd for speed. Might not some ideas prey on the most
susceptible of humans to ensure the fitness of the rest for peaceful occupation
by their memetic brethren? In that same vein, it could be said that humans
choose which ideas to pollinate, optimizing for ideas that appeal to ourselves
the most.
Ideas cooperating to produce a fitter human herd seems pat, but could the truth
be darker? What if our mostly Darwinian universe decreed that there must be
wolves to cull the weak human symbiotes and untenable ideas equally from the
herds of both humans and ideas. These wolves scent out their human prey, the
infirm harborers of unfit ideas, and stalk them until they fall. The complete
destruction of their prey has a threefold result: the thinning of the least fit
humans, the purging of divergent ideas remaining in those hosts, and the birth
of an ever so slightly deadlier predator from the wreckage of its victim.
Disclosure: I recently worked for Google for about a year. It was alright.
Recently, Vic Gundotra of Google+ fame made a bold statement. He
proclaimed
that the lack of write API access to Google+ is born not out of lack of
foresight, planning, or even bandwidth, but out of trepidation, caution, and the
desire to do right by developers.
This is raw, barely-refined bullshit and I regret not being able to respond to
the thread with a pithier snarky comment. The truth is simpler: Google is
full-stop terrible at APIs.
Don’t look at me, it says so right there
As a case study, let’s examine what I had to do in order to use the most
powerful collection of user-generated content that Google makes available to
developers: a user’s email contact list. People who work for consumer-
facing web companies probably know how deeply important having a user’s email
address is for marketing. Despite being invented before I was born, email has
yet to be outmoded as the most effective way to push content to users on demand.
The feature
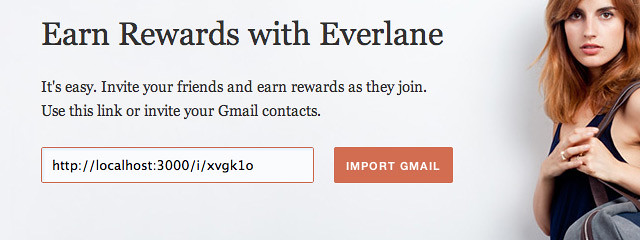
Recently here at Everlane, we thought it might be a good idea to have a
button a user could hit to view a list of their Gmail contacts with portraits,
select some of them, and then have us send those users an invitation email.
Simple, obvious stuff to want to do, right?
What we want to implement
Well, let’s hit the getting started page of the contacts API documentation.
Reading closely seems to reveal that there might already be a library for doing
what we want, which is really nothing more than getting a bunch of names, faces,
and emails. Those geniuses at Google have to have something already made for
this, right? We head over to the libraries and samples page. Cool, a
Javascript library! This could be easy! Nope, they seem to support every
Google API but Contacts. The Google+ read API doesn’t seem to have a good way to
grab emails, either.
That’s fine – we’re pretty decent engineers and can call the Contacts API on
our own. We register our application with the API Console and start reading
about OAuth. Google provides a few authorization schemes. We probably want
the one titled “Client-side Applications”, which saves us the complexity of
an application server having to be aware of any sensitive information.
API woes
Now we can finally ask the Contacts API for a list of contacts! Easy enough,
right? We’ll just do a JSONP request to get around the cross-domain
restrictions.
varauthParams={access_token:...,token_type:...};// from Google oAuth$.ajax({url:'https://www.google.com/m8/feeds/contacts/default/full',dataType:'jsonp',data:authParams,success:function(data){console.log(data);}});
What does this give us? To our slow and creeping horror, we get back something
like this for every contact:
You take several deep breaths. You ignore the fact that you are fetching roughly
1kb of data per contact (out of potentially thousands) to get a name, an email,
and the URL of an image. “Okay”, you think to yourself, “this is still
salvageable. I can parse XML on the client. In fact, jQuery can probably do it
for me.” You take a quick stab at grabbing names and emails.
A quick browser test shows that this only appears to work in Chrome. A bit more
digging turns up, to your chagrin, that jQuery has trouble finding namespaced
elements like “" in XML documents on different browsers. You Google
around and find a fix:
For now, you ignore how inefficient this is, hoping merely to reach
functionality. It works! Now you want to add images. It looks like one of the
link elements under <entry> appears to point to an image for that contact. You
fiddle around on the console:
Attempting to load this in your browser gives you a 401. Taking a look a the
photo management section of the docs seems to suggest you need to
additionally apply auth credentials to this url. You amend your code:
Unfortunately, only a few images load. What’s going on? You squint at the docs
more closely.
Note: If a contact does not have a photo, then the photo link element has no
gd:etag attribute.
Great, so some image links have a magic attribute on them that says they’re real
images. You wonder why Google even bothers returning image links for photos that
don’t exist. You try something like the following:
.find('link[type="image/*"][gd\\:etag]')// or even.find('link[type="image/*"][gd:etag]')// nope? how about.find('link[type="image/*"][etag]')
But no, jQuery can’t deal with namespaced attribute selection, at all, so you
arrive at:
This time, a few more photos load, but then they stop coming. The console shows
a few successful image loads, but most of the requests for images returned with
503 (Service Unavailable) errors. You realize, after an hour or so, that
each image load is being counted as an API call against you, and that there must
be some rate limiting in place.
Naturally, this fact is completely undocumented. Playing around with the
code, you find that Google doesn’t like it if you have more than one in-flight
API request at a time. You come up with essentially the opposite of an image
preloader to stagger image loading:
varimageUrls=['https://...',...];functionstaggerImages(index){if (index==imageUrls.length)return;varimg=newImage();img.onload=function(){setTimeout(function(){// Load the next image 100ms after this one finishes loadingstaggerImages(index+1);},100);};img.src=imageUrls[index];$('body').append(img);}staggerImages(0);
Whew, that was fun, right? At this point it seems like a good idea to try to
sort contacts by some sort of relevance metric. Unfortunately, the Contacts API
doesn’t support this at all. Oh well. You give up, having reached something
approximating your original goals.
What have we learned?
Google doesn’t get JSON.
Google can’t design clean APIs or document them well.
Despite their browser-first mantra, Google doesn’t put out first-party
Javascript libraries for the browser.
Vic Gundotra is soooooo lying.
Developers waiting for Google+ to deliver on its full, API-wonderland potential:
you should probably just give up. What are the odds that this whole time,
they’ve been cooking up the perfect write API, replete with features, libraries,
and documentation? I’m betting that they’re doing exactly what I did when I
worked for Google: absolutely nothing of importance.
Lastly, we’re always on the lookout for talented developers who are interested
in the fashion space here at Everlane. You don’t need to own more than one
pair of shoes. My love of fashion is born of William Gibson novels and is almost
entirely academic. If you’re interested, check out our jobs page or send
me an email at me@vincentwoo.com.
P.S. Yes, I am aware there is an older gdata library that can
potentially handle contacts. I might have used it if it wasn’t deprecated or
Google had made any mention of it whatsoever on their Contacts API page.