This piece originally ran on Medium and is reproduced here with some small formatting differences.
How Aaron Peskin got his illegally merged $1.5M “monster” home
San Francisco Supervisor Aaron Peskin is back in the news, proposing legislation with the ostensible purpose of preserving rent controlled apartments by preventing them from being converted into “monster” homes. His legislation would require lengthy and expensive conditional use permits for even basic changes to buildings. Disregarding the fact that this is obviously a bill designed to lengthen San Francisco’s already byzantine permitting process, Peskin is personally guilty of the very crime he publicly crusades against. This is the strange, ridiculous, and criminal story of how Aaron Peskin lives in a monster home that used to be a rent-controlled duplex.
Aaron “The Napoleon of North Beach” Peskin
Timeline
Oct. 2000: A wealthy San Francisco investment adviser named William Brady purchases the 224 Filbert property for $1.5M. Brady then sells to the property to Joanne Trafton for $1.5M, three weeks later. Trafton is the wealthy owner of several other nearby Telegraph Hill properties.
Nov. 2000: Peskin wins the election for District 3 amid a crowded field of contenders.
May 2001: Trafton receives a permit to perform a $25,000 kitchen renovation of 224 Filbert. Around the same time of the ostensible kitchen renovation, she also illegally performs work to merge the two units of the duplex by removing the kitchen in one unit and adding an internal staircase.
Oct. 2001: Trafton applies for a permit to retroactively legitimize having merged the property into a single family home. The Telegraph Hill Dwellers (THD), a large neighborhood association that Peskin was the president of until his election, sends a letter opposing the merger.
Simultaneously, Planning staff recommends that the Planning Commission exercise its discretionary review powers to deny the merger. Trafton, defeated, withdraws her application.
Dec. 2002: Peskin’s parents begin transferring ownership of the property to Peskin and his wife. This continued gradually and eventually concluded in April of 2007, with Aaron Peskin and his wife owning 100% of the property free and clear.
Oct. 2004: An unnamed complainant (likely a neighbor) lodges a complaint with the Department of Building Inspection that the property has been illegally merged. This complaint is abated by DBI.
Analysis
When Trafton acquired 224 Filbert in 2001, she paid $1.5M for roughly 1500 sqft of real estate, or approximately $1000 per sqft. At the time, this was very expensive for an older duplex of two small one-bedroom units. However, a single-family home of the same size could plausibly sell for $1.5M, and would retain its value better than the two individual units. It is likely that Trafton planned her conversion from the outset, and quickly acquired her “cover” permit to perform kitchen renovations soon after buying the property.
Aaron Peskin’s wife, Nancy Shanahan, had already paid the city to receive advance notice of any permit applications for 224 Filbert, and was notified when Trafton applied for her permits. Shanahan serves as the Vice President of the Telegraph Hill Dwellers as of the writing of this piece, and Peskin was their President for several years before his election. After discovering (likely through Shanahan or Peskin) that Trafton was filing for her permits, the THD wrote a letter to support Planning’s recommendation to deny the merger. My point with all of this is that there is no plausible way that the Peskins could have been ignorant of the illegal merger aspect of 224 Filbert. It even looks like it is fairly likely that they themselves are responsible for galvanizing the official opposition to the merger.
Left: A photo of the internal staircase from 2001 report. Right: the staircase remains as of 2019.
A large part of this case rests on information discovered during Planning’s staff-initiated discretionary review of the merger. According to this document, Trafton performed renovations and illegally merged the duplex before filing with the city to formally acknowledge the property as a single family home. The smoking gun in the report is a photo of a newly-built internal staircase connecting the two units.
In the face of the organized opposition from both Planning and the Supervisor of the neighborhood, Trafton withdrew her application. Because Trafton withdrew her application instead of continuing her discretionary review, she was not required to acquire permits to return the building to its original condition as a duplex. Trafton was left in a difficult position. She had purchased the property for $1.5M, but now had no way of selling the property for that much as a single family home. She also could not sell it as a duplex just to recoup some of her losses without performing additional work to undo her merger.
I, of course, cannot be privy to whatever discussions she had with Aaron Peskin, but she resolved to sell the property to Peskin’s parents for half of what she had paid. It is likely that this was a matter of convenience for her — it allowed her to get rid of what was becoming a toxic asset quickly and quietly. Even though the sale price was half of what she had paid, she wouldn’t have to bother with additional construction work to restore the property to a duplex. Peskin, in turn, would be one of few buyers who could safeguard this illegally merged home from city enforcement. This deal, of course, is an astounding act of political corruption and conflict of interest.
It is important to state, once again, that this home is absolutely not a duplex today. Disregarding the still visible internal staircase, if the home was still a duplex, one would imagine that Peskin was residing in one of the two units and renting out the other. Peskin is required to report his income as an elected official, but no such income from the rental of the other 224 Filbert “unit” has been disclosed, though he has disclosed income from his other rental properties.
Furthermore, two years after Peskin acquired the property, the Department of Building Inspection (DBI) received a complaint that the building had been merged. The very next day after the complaint was received, Peskin applied for permits to ameliorate DBI’s concerns. He managed to complete the permitting process the very next day after the complaint was filed, a somewhat shocking feat.
Ironically, the permit page lists the building very clearly as a “2 FAMILY DWELLING”.
Strangely, though, this permit mentions only renewing older permits, and not undoing an illegal merger. Even more strangely, despite that, DBI closed its case on the complaint a few days after it was received. I have no explanation for why this happened, as DBI did not take any detailed notes on how this case was handled that I could discover. From how quickly the case proceeded from complaint, to permit acquisition, and finally to abatement, it seems fairly likely that Peskin pulled some strings to get the problem to go away quickly.
To reiterate, there is no version of events where Peskin innocently acquired a home that he didn’t know used to be a duplex. The fight over whether Trafton would be allowed to legitimize her merger happened only a year before he bought the house from her, and he and his wife were essentially the other side of that fight. There is no world where Peskin is conveniently unaware that his home used to be a duplex, because the city still says that it is a duplex on every current record and form related to the property.
There’s a simple case to be made that Peskin’s actions constitute the crime of graft (or extortion). Peskin blocked Trafton’s merger of 224 Filbert and then subsequently occupied it as a merged home. By secretly profiting from the very thing he purported to oppose, Peskin turned his $800,000 home into something worth much more. Taking Trafton’s purchase price at face value, a merged 224 Filbert was worth at least $1.5M. Essentially, Peskin’s use of his power in Telegraph Hill netted him at least $700,000. This transaction’s very existence is at minimum a clear conflict of interest and more likely an abuse of the power of office for personal profit.
Even more shocking, though, is how he could pen an entire bill that uses as its bogeyman the very home he lives in. His 70 page proposal’s ostensible reason for existence is the protection of rent controlled apartments. One wonders how much of the bill he wrote in his stolen rent controlled apartments, or if he felt even a glimmer of guilt while he wrote it.
Postscript
I’d like to thank everyone who helped me think through this case. If this story made you mad, I’d appreciate it if you shared it with, oh, I don’t know, Peskin’s staff? The SF Ethics Commission? DBI? The media? If you want to know more, I’m happy to talk to anyone curious about the details. There’s a bunch of other interesting stuff that didn’t make the cut — ask me about how Trafton sold another two properties on the same street to Peskin’s family (this is true).
On August 28th, the FPPC informed me that they would not take action on my previous complaint, and that if I disagreed, I could file an appeal.
Naturally, I decided to take them up on that. Below, you’ll find the appeal I filed with the FPPC. As of October 9th, they have informed me that the case has been reopened.
To: Galena West, FPPC Chief of Enforcement Division and Erin V. Peth, FPPC Executive Director
Re: FPPC Complaint #COM-07202017-01276
Mr. Sutton, in response to our first complaint, wrote "the FPPC should dismiss [our] complaint because it fails to allege any violation of law." He is incorrect.
Through the discussion outlined in our initial complaint, we have alleged that James David Stearns (Jim Stearns), through Stearns Consulting, LLC, SF Van, LLC (a voter file company Stearns owns), and the Affordable Housing Alliance Political Committee (AHA), violated Government Code §84302, Government Code §83403, California Code of Regulations §18401, and California Code of Regulations §18431.
We have alleged that Stearns, through his single-member LLCs and the AHA, has contributed substantial unreported amounts to certain campaigns, made substantial unreported expenditures on behalf of those campaigns, and engaged in behavior commonly described as political money laundering on behalf of those campaigns.
Background
During the 2016 San Francisco election, Stearns, a well-known San Francisco campaign strategist, was employed by at least twelve different committees, including:
The single largest spender in the 2016 San Francisco General Election, "No on V," a PAC funded by the American Beverage Association and commonly referred to as "Big Soda." Notably, "No on V" spent roughly $22.5 Million on that election, more than every other spender in the election combined.
The "Affordable Housing Alliance Political Action Committee," which was registered as a Slate Mailer Organization for the 2016 election.
Other PACs, including "Coalition to Save Affordable Housing", "Stop the Developer Giveaway", "Jobs, Housing, and Parks Now", "San Francisco Reform Coalition", "Housing Forward SF", and "Coalition to Save Affordable Housing."
Candidates for the San Francisco Board of Supervisors: Sandra Lee Fewer, Dean Preston, Aaron Peskin and Hillary Ronen through the PAC "Working Families for Hillary Ronen."
Between August 30, 2016 and November 21st 2016, the AHA received $389,000 exclusively for "November 2016 Slate Mailers" from:
"No on V", a Stearns client: $280,000, or 72% of total payments.
Other Stearns clients : $36,750, or 9% of total payments.
Board of Supervisor candidates endorsed on AHA mailers:$1,300, or less than 1% of total payments.
All others: $70,950, or 18% of total payments.
$364,525 of the $389,000 paid to the AHA during this period was distributed to Stearns Consulting LLC for the November 2016 Slate Mailers. Stearns Consulting LLC in turn paid $25,915 to SF Van LLC, a voter file company also controlled by Stearns, and $233,299 to designers, printers, mailers, and the USPS. The remaining balance of $129,786 was presumably retained by Stearns as compensation.
Based on this review, it appears that substantially all of the AHA's receipts and expenses were controlled or directed by Stearns, either through contributions by his clients or disbursements to Stearns Consulting, LLC. His clients provided 81% of the AHA's funding during November, and Stearns decided how 93% of the AHA's money was spent.
The Sandra Lee Fewer Campaign Committee
In the case of the Sandra Lee Fewer Campaign for District 1 Supervisor, Stearns arranged undisclosed contributions to Fewer's campaign and expenditures on behalf of Fewer's campaign by directing funds from "No on V" through the AHA. Stearns then produced slate mailers that directly benefited Fewer's campaign by attacking her only real opponent, Marjan Philhour, as seen below.
Fewer won with 39.64% of the vote, with Philhour in second place with 34.95% of the vote. The next candidate, David Lee, was a distant third at 10.73% of the vote.
Stearns laundered funds from one his clients, "No on V", through another of his clients, the AHA, for the benefit of yet another one of his clients, the Sandra Fewer campaign. The Fewer campaign could not accept those funds directly as it was publicly financed. Stearns did not report any of these contributions to or expenditures on behalf of Fewer's campaign.
Other Beneficiary Committees
Fewer was a significant beneficiary of Stearns' money laundering activities, but was not the only beneficiary. Below is a list of Stearns clients that were included on AHA mailers in 2016:
Client
Position endorsed by AHA?
Amount paid to AHA
No on V, Enough is Enough Don't tax our groceries
Yes
$280,000
Jobs Housing Parks Now Yes on O
Yes
$25,000
Coalition to Save Affordable Housing Yes on C
Yes
$6,500
Stop Developer giveaways No on P, No on Q
Yes
$3,000
San Francisco Reform Coalition Yes on H
Yes
$1,000
Rafael Mandelman
Yes
$750
Housing Forward SF Yes on C, M No on P, U
Yes
$500
Aaron Peskin for Supervisor
Yes
$250
Sandra Lee Fewer for Supervisor 2016
Yes
$250
Working Families for Hillary Ronen (Client)/Hillary Ronen for Supervisor 2016 (Candidate & Contributor)
Yes
$250
Dean Preston for Supervisor 2016
Yes
$250
Affordable San Francisco for All Yes on C
Yes
$0
4 for Reform, Yes on D, H, L, M
Yes
$0
Substantially all of Stearns' 2016 clients were supported by mailers sent by the AHA, which was in turn financed largely by "No on V" and other Stearns clients.
Relevant Memoranda and Analysis
FPPC Green Letter I-93-376
"…if a committee makes a payment to the slate mailer organization at the behest of a candidate, the committee would be making a non-monetary contribution to the candidate."
"If the payment was made and earmarked to support a specific candidate but was not made at the behest of the candidate, the committee would be making an independent expenditure on behalf of the candidate."
FPPC Sivesind Letter I-96-279
"…if a candidate or ballot measure committee pays an inflated rate to appear on a slate mailer in order to "induce" the organization to include another candidate or measure on the slate mailer, some portion of the payment will constitute a contribution or an independent expenditure by the paying candidate or committee on behalf of the non-paying candidate or ballot measure."
In the Green Letter, quoted above, the FPPC explained that payments made by a committee to an SMO are considered a campaign contribution if done at the behest of a candidate. In the Sivesind Letter, also quoted above, the FPPC explained that a donor committee's use of inflated payments for slate mailers to induce an SMO to benefit a candidate or measure would be considered a contribution or independent expenditure.
Stearns was employed by the donor committees, the SMO, and the candidates. Stearns therefore could not have acted independently as part of the donor campaign committees that funded the November 2016 Slate Mailers, the SMO that produced the November 2016 Slate Mailers, and the beneficiary campaign committees that were endorsed on the November 2016 Slate Mailers.
The FPPC has established the precedent necessary to censure Stearns' behavior. His position as simultaneous campaign consultant to multiple committees, the dramatic disproportionality of payment size to the AHA, and the preponderance of his clients on the AHA's mailers all lend significant credence to the charge that Stearns arranged the "No on V" payments for the benefit of his clients. Both the Green and Sivesind letters support the theory that these payments are in fact either unreported campaign contributions or independent expenditures.
List of Alleged Violations
The Affordable Housing Alliance Political Action Committee was effectively controlled by James David Stearns, directly and through his single-member LLCs, Stearns Consulting LLC and SF Van LLC.
Stearns, through his single-member LLC, Stearns Consulting, LLC, received $364,525 from his client, the Affordable Housing Alliance Political Action Committee, and did not properly report these payments as contributions to his clients in violation of Government Code §84302 and California Code of Regulations §18401.
Stearns, through the Affordable Housing Alliance Political Action Committee, received $280,000 from his client, "No On V," and did not properly report these payments as contributions to his clients in violation of Government Code §84302 and California Code of Regulations §18401.
Stearns, through his single-member LLCs, Stearns Consulting, LLC and SF Van, LLC, made $259,214 in expenditures for political purposes and did not properly report these as expenditures on behalf of his clients in violation of Government Code §84303 and California Code of Regulations §18431.
Stearns, through the Affordable Housing Alliance Political Action Committee, made $364,525 in expenditures for political purposes and did not properly report these as expenditures on behalf of his clients in violation of Government Code §84303 and California Code of Regulations §18431.
Stearns, in addition to violating the Government Code Sections and regulations listed above, likely violated numerous related statutes in conducting his money laundering activities. To the extent that a specific allegation has not been made above, we allege any violations of law related to the money laundering activities we have described.
We ask that the FPPC investigate these allegations thoroughly and issue a clear judgment discouraging money laundering through SMOs. The practical effect of not taking action will be to legitimize and proliferate this behavior in the upcoming 2018 election.
July 21st update: Rachel Swan wrote about this complaint for the Chronicle, which includes a short, unsatisfying response from Stearns.
August 3rd update: The FPPC has responded that they need a few more weeks to judge whether they should pursue a claim. The letter indicates that Stearns has lawyered up.
To whom it may concern at the California Fair Political Practices Commission,
Jim Stearns, a political consultant in San Francisco, has evaded laws governing independent expenditures by coordinating with a political candidate and laundering money through a Slate Mailer Organization (SMO). To my knowledge, this is a novel means of avoiding coordination restrictions that typically govern external spending on candidate campaigns. Normally, independent expenditures like PACs are expressly forbidden from communicating with a campaign.
During the 2016 San Francisco election, Jim Stearns was employed as the sole campaign consultant of both the Sandra Fewer campaign and the Affordable Housing Alliance. Stearns used his position at both groups to campaign for Fewer from both inside and outside the campaign. Typically, illegal coordination between candidates and external groups occurs via passed messages or illicit telephone calls. In this case, Jim Stearns was brazenly coordinating with himself.
Election authorities should quickly issue a mandate explicitly banning this behavior. If they do not, the tactics employed by Stearns will become the de-facto standard for every campaign, and will drastically undermine campaign finance transparency.
Background
In 2016, many candidates ran for the position of District 1 Supervisor to replace Supervisor Eric Mar. District 1 is also known as the Richmond neighborhood of western San Francisco. The two leading candidates were Sandra Fewer and Marjan Philhour. The Fewer campaign engaged Stearns Consulting (Jim Stearns’ one-man office) as their campaign consultant. Meanwhile, the Affordable Housing Alliance (AHA) hired Stearns for the same role.
The AHA was registered as a Slate Mailer Organization. “Slate mailers” are pieces of paper mass printed with support for or opposition to a list of candidates and ballot measures and mailed to voters. Slate Mailer Organizations (SMOs) sell placement on these mailers to campaigns, and are technically defined as entities that receive payments of $500 or more to support four or more such campaigns (Gov. Code 82048.3, 82048.4.)
Typically, an SMO will approach candidates or ballot measure campaigns that it favors and say, “Hey, we’d love to put you on our slate to endorse you. Can you pay us $500?” After all the campaigns pay up, the SMO mails out this combined slate to voters. The SMO gets to pocket the difference between how much it cost to mail the slates and how much it raised from campaigns, which is why so many of them are for-profit ventures. Here’s a sample image provided by the FPPC as an example of how one of these slate mailers should look:
Individuals and organizations making independent expenditures, typically PACs, are not allowed to communicate with campaigns, but SMOs are free to do so for the purposes of arranging payment from the campaign. This is a reflection of what is assumed to be the fundamental difference between an SMO and a PAC: an SMO raises money from campaigns, but a PAC raises money for campaigns. This very important distinction is why SMOs are allowed to communicate with campaigns.
However, this distinction has broken down with Jim Stearns and the AHA. Not only did Stearns serve on both the Fewer and AHA campaigns, he raised funds at the AHA while representing the Fewer campaign and coordinated the the marketing efforts of both campaigns simultaneously. He essentially had a secret slush fund to draw on while advocating for Fewer.
SMO Irregularities
The AHA deviated from the standard SMO playbook in a number of key ways that call its status as a legitimate SMO into question. Firstly, their slates don’t seem awfully much like slates. I’ve attached three “slate mailers” sent by the AHA in the Richmond. In each, three out of the four pages visible on the mailer are solely devoted to attacking Fewer’s opponent, Philhour. The remaining page makes only a cursory endorsement of three citywide ballot measures, and makes no mention of endorsing any particular political candidate.
This is very unusual for a Slate Mailer Organization, and is behavior more typical of a standard PAC. It’s not clear if attack ads can even be considered slates at all. The Fair Political Practices Commission (FPPC) manual on SMOs hasn’t addressed the issue yet. Slates often endorse a “No” vote for measures they’re opposed to, but these AHA “slates” devoted 75% of their space to attacking a candidate, and then didn’t even bother to endorse the opponent the AHA presumably supported. It seems clear that these were simply attack ads with a small appendix to have minimum plausible deniability that they were really slates.
Secondly, as mentioned, SMOs usually raise money directly from candidates and ballot measures in return for advertising them in their mailers. However, a cursory look at the AHA’s funding sources reveals that of the $507,900 it raised for the election, $280,000 of that money was raised from only one source: the American Beverage Association, colloquially known as “Big Soda.” The next largest customer of the AHA paid $20,000 for the endorsement of three ballot measures. In 2016, Big Soda spent over $22 million through the “No on V PAC” (FFPC ID 1382995) to defeat Prop V, a proposed tax increase on soda sales. Filings show that this PAC also paid Jim Stearns $40,000 to assist with their campaign as well.
This is a very strange situation for an SMO, which typically raises a large amount from many customers who pay roughly comparable amounts of money in order to be featured on the slate. Here, Big Soda put in more than half of all money raised by the AHA, and ten times as much as anyone else. One would imagine that Big Soda’s issue, opposition to Prop V, would feature prominently in all of the AHA’s mailers. Oddly, Prop V is quite literally not even mentioned in the mailers that attack Marjan Philhour. This behavior is very strange for an SMO, but not if you consider the AHA to actually be a covert PAC with the purpose of electing Sandra Fewer.
Helpfully, the FPPC has touched on a related matter. In Finley Letter, A-92-219, a one Lowell Finley asked the FPPC what would happen if his SMO received donations from a third party who was only contributing to help defray the costs of the mailer. That is, from someone who was not paying to appear on the mailer themselves. The FPPC concluded that if they raised more than $1,000 this way in a year, the SMO would have to file as a “recipient committee,” which is essentially a traditional independent expenditure PAC, with all the attendant regulations. This ruling is helpful in the case of the AHA because Big Soda paid a surprisingly large sum of money to not appear in many mailers sent by the AHA, which essentially amounts to defraying the costs of the AHA’s campaign. Notably, the AHA is already registered as a recipient committee, indicating it has operated as a PAC in the past.
Thirdly, the slates sent by the AHA were remarkably similar to mailers sent by the Fewer campaign. This was likely because Stearns was making the mailers for both campaigns. For instance, the Fewer campaign adopted the slogan “San Francisco is not for sale.” Mailers sent by the AHA featured similar slogans like “The Richmond is not for sale,” which is a bit ironic considering who paid for them. Likewise, mailers from both were printed on the same paper, in the same size, and with the same font. Is a slate designed by a political consultant from an individual candidate campaign really an independent slate?
Analysis
It’s hard to escape the conclusion that the AHA was exploiting its status as an SMO. However, one must ask why Stearns would take such risks. It would be perfectly legal for Big Soda to donate to a normal, regulated PAC. However, being in charge of both an SMO and Fewer’s political campaign gave Stearns numerous advantages during the 2016 election.
Firstly, this arrangement gave Stearns much more power over fundraising and marketing. By controlling both the AHA and the Fewer campaigns, he avoided having to worry about whether an independent PAC could actually produce good ads that supported the Fewer campaign. In this particular case, Stearns could send exactly which negative ads he wanted, with total control over appearance and timing. Additionally, since these negative ads were not attributed to Sandra Fewer, he could avoid the appearance of running a negative campaign. This is especially important given SF’s ranked choice voting system.
It’s also likely that the money from Big Soda would not have been spent on Fewer if Stearns was not also the consultant for the AHA. Big Soda’s goal in the 2016 election was to prevent the passage of Prop V. Supporting Sandra Fewer did not advance that goal. However, as Stearns was already a consultant for Big Soda, he likely managed to arrange their contribution to the AHA, in exchange for running some mailers with a No on V endorsement. The AHA certainly did run such mailers, but they also used their funds to run ads attacking Fewer’s opponent. If Stearns had not been employed by the AHA, Big Soda may still have attempted to buy an AHA endorsement, but it’s not likely those funds would have been spent campaigning directly for Fewer.
Secondly, the AHA is registered as a statewide Slate Mailer Organization. This means they report fundraising and spending to the state, not to the San Francisco Ethics Commission. Practically speaking, this allowed the Fewer campaign to conceal that a large amount of external money had been raised on their behalf. From a SF Examiner article entitled “SF’s million-dollar supervisor races”:
Philhour has received $336,000 in campaign contributions, which are capped at $500 per donor, as of Monday. She has also benefited from more than $700,000 in third-party spending, which has no limits, according to the Ethics Commission.
[…]
The total spending against Philhour has reached $450,000 in the contest, according to the Ethics Commission. Fewer’s campaign has received about $360,000 in contributions and some $74,000 in third-party spending benefiting her.
At the time of writing of that article, the official tally of third-party spending for the Fewer campaign was only $74,000. However, if the AHA had registered as a standard PAC and not a Slate Mailer Organization, they would have had to report the money they were spending on Fewer’s behalf. The money that “normal” SMOs spend to mail slates does not count as dollars spent in support of a candidate because the candidate is the one paying the SMO for their services. Since Fewer only paid the AHA $250 for the privilege of being promoted by their mailers, she received an exceptionally good deal when Big Soda happened to bankroll most of the mailers. This allowed her to keep her “third-party spending” number down, as tracked by the SF Ethics Commission, and artificially create the perception of being more of a grassroots candidate than her opponent.
Being a statewide SMO also allowed the AHA to avoid reporting their mailers to the city. San Francisco has the relatively unique requirement that PACs send copies of their mailers to the SF Ethics Commission (SF Campaign and Governmental Conduct Code 1.161). Since the AHA was not a PAC, it was not required to file their attack mailers with the city, despite clearly advocating for a particular city candidate. This made it harder to track down their mailers, as I had to acquire them from citizens who happened to have saved the ones they received in the mail.
Thirdly, this arrangement was simply very lucrative for Stearns. He was able to charge the AHA about $479,000 over the course of the 2016 election. Of that, $334,000 went to the design, printing, and mailing of the slates, which left him with a profit of about $145,000. Being the consultant for the AHA as well as Fewer campaign gave him an extra income stream, which wouldn’t have been possible if he was limited to consulting for only one of the two.
Requested Action
The FPPC should censure or fine Stearns and issue stronger requirements for what actually constitutes an independent SMO. These requirements should explicitly prohibit deep coordination with campaigns and place additional constraints on mailer design.
Regards,
Vincent Woo
CC:
Maggy Krell, Special Prosecutions Unit, Office of the Attorney General
June Cravett, Special Operations Department, San Francisco District Attorney
Pamela Parra, Political Reform Audit Manager, Franchise Tax Board
Peter Keane, Chairperson, San Francisco Ethics Commission
This piece also ran as part of Heather Knight’s column in the San Francisco Chronicle on May 23rd, 2017. A point that I should correct is that 501(c)(3)s actually do pay payroll tax. However, the nonprofit entity itself does not pay federal income tax, and of course donations are tax-deductible for donors, which is the main benefit.
To the IRS and the public,
48 Hills is an independent publication run by the San Francisco Media Center (SFMC). Its editor and executive director, Tim Redmond, writes about San Francisco current events and politics. SFMC is also an IRS-approved 501(c)(3) nonprofit entity, which not only exempts SFMC from paying taxes on Tim Redmond’s salary, but also grants a tax deduction to any donor who contributes to 48 Hills. This would all be well and good if it weren’t for the fact that 48 Hills routinely engages in one of the acts expressly forbidden to a 501(c)(3): electioneering.
The IRS is crystal clear on this mandate: “Under the Internal Revenue Code, all section 501(c)(3) organizations are absolutely prohibited from directly or indirectly participating in, or intervening in, any political campaign on behalf of (or in opposition to) any candidate for elective public office.” 48 Hills as a publication is a unilateral supporter of the “progressive” faction of the Democratic party in San Francisco, and does not hesitate to attack any politician outside of this camp. This is not a free speech issue. Most SF newspapers are not incorporated as 501(c)(3)s and do not receive special tax treatment. 48 Hills is quite likely the only SF politics-focused publication that also happens to be a 501(c)(3).
Background (San Francisco Politics)
San Francisco is a very liberal city. All of its elected officials are currently, to my knowledge, Democrats. Although not formally institutionalized, there are two main political factions in San Francisco, which are generally described as the “progressives” and the “moderates.” Both are still Democratic groups, but often differ significantly in their opinions on public policy. A relatively neutral explanation of both parties is that moderates are more in favor of public-private partnerships, and progressives are more leery of industry and privatization.
In a March 2016 piece entitled “Two-Party Town,” Tim Redmond himself identifies the two parties and his preference for one of them:
I am increasingly coming to believe that San Francisco is now a two-party city – and oddly, we are seeing that reflected in the race to determine who will run the Democratic Party.
Republicans are almost entirely irrelevant in San Francisco (the last GOP office holder, BART Board member James Fang, lost his seat two years ago. There hasn’t been a Republican in any significant elected office in years). There’s a modest Green Party…
But the real two-party system right now is between the progressive party and the Ed Lee/real-estate/tech mogul party…
…
But overall, they are two very distinct parties – and you aren’t going to see much crossover in endorsements, political activism, or political fundraising this fall.
Indeed, 48 Hill’s endorsements are almost exclusively “progressive.” The 48 Hills website describes itself as “the progressive daily that San Francisco has always needed” whose writers and editors are “proud of [their] politics.” Moreover, in his “Two-Party Town” piece, Redmond adds:
Progressives are often fractious, and that’s fine – we argue, we care about policy, we aren’t afraid to disagree. But right now, the progressive community is pretty unified around the June and November elections. (Emphasis added.)
Simply put, 48 Hills self-identifies very strongly with just one particular political group in San Francisco.
Electioneering
The IRS ban on 501(c)(3) electioneering is absolute, which means not even “a little bit” of campaigning for a candidate is allowed. Again, the relevant section reads: “501(c)(3) organizations are absolutely prohibited from directly or indirectly participating in, or intervening in, any political campaign on behalf of (or in opposition to) any candidate for elective public office.”
Moreover, the prohibition applies to a wide range of activities beyond explicitly urging people to vote for or against certain candidates. It applies to any “activities that may be beneficial or detrimental to any particular candidate” (FS-2004-14). A 501(c)(3) organization violates the ban when there is “some reasonably overt indication in [its] communications … that the organization supports or opposes a particular candidate (or slate of candidates) in an election” (2002 CPE Text5, p 345). This occurs when the content or structure of the publication evidences a bias or preference with respect to the views of any candidate or group of candidates (Revenue Ruling 78-248; Private Letter Ruling 199925051).
For example, in Branch Ministries v. Rossotti (D.D.C. 1999), the District Court upheld the IRS’s determination that a church had intervened in a campaign by placing an ad that suggested that Bill Clinton’s proposed policies were contrary to “God’s law,” and that concluded with “How then can we vote for Bill Clinton?” The takeaway here is that any statement, rhetorical or otherwise, that induces the reader to vote a certain way is expressly forbidden to charitable organizations like 48 Hills.
Redmond may try to claim that he is solely performing the service of educating his readership. This is a common enough defense that the IRS has given guidance on it as well:
…certain voter education activities (including presenting public forums and publishing voter education guides) conducted in a non-partisan manner do not constitute prohibited political campaign activity. In addition, other activities intended to encourage people to participate in the electoral process, such as voter registration and get-out-the-vote drives, would not be prohibited political campaign activity if conducted in a non-partisan manner.
On the other hand, voter education or registration activities with evidence of bias that (a) would favor one candidate over another; (b) oppose a candidate in some manner; or (c) have the effect of favoring a candidate or group of candidates, will constitute prohibited participation or intervention.
There is no excuse for a 501(c)(3) publisher to say that it is simply covering current events, when it is in fact expressing a highly partisan bias. The Treasury makes it clear that educating the public doesn’t get you a free pass when it comes to electioneering: “Educating the public is not inherently inconsistent with the activity of impermissibly intervening in a political campaign” (Technical Advice Memorandum 8936002). 48 Hills is not treading in a gray area. It is far, far over the allowable line for charitable entities, which I will show in more detail.
Specific Electioneering Violations
In November 2016, San Francisco held elections for five members of its Board of Supervisors, and for the State Senator representing the city. 48 Hills consistently ran afoul of the electioneering ban during this election by hugely favoring progressive candidates. It also did so in many other elections, but I’ll focus on this one for simplicity’s sake. For reference, here is the list of candidates in this election by faction:
Position
Progressive Candidate
Other Candidate(s)
District 1 Supervisor
Sandra Lee Fewer
Marjan Philhour
District 3 Supervisor
Aaron Peskin
Various
District 5 Supervisor
Dean Preston
London Breed
District 7 Supervisor
Norman Yee
Joel Engardio and Others
District 9 Supervisor
Hilary Ronen
Josh Arce
District 11 Supervisor
Kimberly Alvarenga
Ahsha Safai
State Senate
Supervisor Jane Kim
Supervisor Scott Wiener
In Forum: What the Nov. elections mean (October 2016), Redmond writes “Control of the Board of Supes is at stake – and that means the policy direction of the city. If the mayor’s allies wind up back in charge, it will be two difficult years.” “Mayor’s allies” refers here to the candidates running against his favored progressive candidates. He then goes on to say “If you want help sorting all of this out (beyond, of course, going to the Bay Guardian endorsements)…” which is an explicit and direct link to a slate endorsing those same progressive candidates. This is a violation of previously mentioned IRS guidance to not endorse a particular candidate. The link to the Bay Guardian slate is even more specifically and egregiously a violation of prohibitions on “Linking to web pages containing materials favoring or opposing a candidate for public office” (Revenue Ruling 2007-41). It also bears mentioning that the Bay Guardian is a 501(c)(4) also owned by Tim Redmond, and both it and 48 Hills are headquartered at his home in San Francisco.
It’s a good thing nobody pays attention to the Chronicle’s endorsements, since the paper’s choices for the Board of Supes races are just embarrassing. Except for Aaron Peskin, who got the nod in part because he is running essentially unopposed, the lineup completely excludes the progressives, even when the moderate candidate is really weak. Ahsha Safai? Nato Green has an excellent piece noting that he has “a distinguished record of not doing much.” (Except helping screw up the Housing Authority):
…
Josh Arce? Joel Engardio?
Oh well. As I said, nobody listens to the Chron anyway.
This is a very clear disapproval of candidates Safai, Arce, and Engardio, who ran against progressive candidates. Again, this is in direct violation of the very simple IRS rule that you not express an opinion on specific candidates. It is worth noting that unlike 48 Hills, The Chronicle is not a 501(c)(3) and does not violate the law by publishing candidate endorsements.
48 Hills also uses a host of code words to signal disapproval for candidates. In The story Ahsha Safai doesn’t tell in his campaign for supervisor, Redmond describes Safai as a “real-estate speculator, house flipper.” In a piece entitled Wiener featured guest at banquet of landlord activist who opposes transgender rights, he labels the sponsor of an event then-Supervisor Wiener attended as “one of the more radical landlord-rights advocates in the city.” These code words serve the transparent purpose of indicating disapproval for the associated candidates in their elections through disdain for the real-estate industry. This messaging via implicit understanding of code words is, again, expressly forbidden (2002 CPE Text, p. 345).
I have attached, in a companion binder of evidence, many more violations that also span other elections, such as the election for members of the San Francisco Democratic Committee Central Committee in June 2016. In reading through 48 Hills’ long publication history, one cannot avoid the impression that it is an official campaign mouthpiece of specific “progressive” candidates in San Francisco. It regularly defends them during their campaigns, levels charges against their opponents, and communicates the “correct” electoral outcome to its readers.
Conclusion
I don’t doubt that Tim Redmond and the staff at 48 Hills believe they are advocating in good faith, nor do I think they shouldn’t be allowed to write the things they write. The populace is best served by open discourse. Though I strongly disagree with many things that 48 Hills has published, I find, in fact, that it is useful to have the opposition’s ideology laid out so plainly.
However, I can’t stand for rank hypocrisy. 48 Hills has written many times about how its political opponents are financially corrupt. In The Panama Papers and SF’s housing crisis, Redmond asserts “But it would be completely insane to believe that all of that new housing that the mayor is praising is being built without some of this illegal, secretive cash.” This publication has avoided most of its tax obligation while failing to follow even basic guidelines about how not to commit electioneering. The irony of it speculating on the financial corruption of others is almost palpable.
Requested Action
The IRS should immediately revoke the San Francisco Progressive Media Center’s 501(c)(3) status. Per Internal Revenue Code section 4955, it should also impose a 10% tax on the entity for all campaign-related expenditures (including staff salary for all relevant articles).
I wrote an opinion piece for the SF Chronicle. They ran it with some great edits for length, so I figured I’d put my original, longer, and worse version here for posterity’s sake.
San Francisco is one of the most progressive cities in the nation, especially when it comes to national immigration. We believe so much in the natural right of people to join us here in America that we fought to keep our status as sanctuary city even in the face of being federally defunded for it. We pride ourselves in our rejection of plans to tighten immigration controls and deport undocumented immigrants. Yet take that same kind of conversation to the local level and all bets are off. City meetings have become heated, divisive, and prone to rhetoric where we openly discuss exactly which kinds of people we want to keep out of our city.
Consider the recent Board of Supervisors meeting to appeal the plan to build housing at 1515 Van Ness. Despite the project’s plan to rent 25% of its units at a below market rate, many members of the neighborhood group Calle 24 expressed anger that the project might bring tech workers into the Latino Cultural District. Elsewhere in the city, members of the Forest Hills homeowners association opposed a project that would convert a church into 100% affordable housing for seniors and the formerly homeless. One of the grievances aired was that it might bring mentally unstable or drug addicted people into Forest Hills.
Both of these groups are reacting to the threat of change to their neighborhood. Calle 24 is opposing what they see as increased gentrification and a loss of Latino identity in the Mission. Forest Hills is attempting to preserve their idyllic suburb-within-a-city aesthetic of detached single family homes. In both cases, residents took it as a given that they were within their rights to control the demographic makeup of their own neighborhoods. Like conservatives who see entry to the country as discretionary, these city residents see entry into their own neighborhood as something they have veto power over.
This isn’t an ethically coherent position for San Franciscans to hold. If we so strongly believe that national immigration is a human right, it seems strange to only block migration into our own neighborhood. Where do we get to draw the line? I think how people feel about this issue boils down to whether they see migration as a right or a privilege. Conservatives in America see national immigration as a privilege we need to carefully dole out. Liberals tend to see immigration as a human right that needs to be protected. San Francisco progressives view living in certain neighborhoods as a privilege to be earned, and see nothing wrong with preventing certain groups of people from moving into those neighborhoods.
Tech workers have now become the most visible of these groups. As the most recent affluent demographic to appear in San Francisco, tech workers have been been cast as shallow opportunists who indifferently displace existing residents. However, most tech workers who move here are simply migrants from less affluent parts of the country. They’re people from places like the midwest who are just trying to find good jobs in one of the last functioning economic engines in the country. If we believe that San Francisco should be a shelter for people from less prosperous countries, why shouldn’t it also be a shelter for people from less prosperous parts of our own country? Even more pointedly, more than a third of Silicon Valley tech workers are immigrants themselves. For many people in China, India, and Eastern Europe, working in technology is one of the few ways out of their country and into ours.
Neighborhood activists want to protect their vision of San Francisco, and that is absolutely a noble purpose. However, blocking future residents isn’t the way to go about it. How would you even do it? The current approach of attempting to just halt construction hasn’t proven effective at preserving neighborhood aesthetics. To truly control who lived in a neighborhood, you’d have to create some official tribunal that would essentially have the ability to vet applicants by their demographics. This is would be very dangerous and likely illegal, especially when considering the Fair Housing Act. It’s hardly a progressive idea to institutionalize exclusionary policy, especially deliberately.
If we really believe that migration is a human right and not a privilege extended at the discretion of current residents, then we need to acknowledge that neighborhood meetings where people feel entitled to debate the virtues of future residents are anti-migration by definition. We need to acknowledge that making room for, say, an Indian tech worker on an H1-B who is trying to get a green card serves the very same ideological purpose as making room for an undocumented worker from Mexico. Denying migration to our city to selective groups of people is impractical and counter to our very own progressive values.
 Aaron “The Napoleon of North Beach” Peskin
Aaron “The Napoleon of North Beach” Peskin
 Left: A photo of the internal staircase from 2001 report. Right: the staircase remains as of 2019.
Left: A photo of the internal staircase from 2001 report. Right: the staircase remains as of 2019.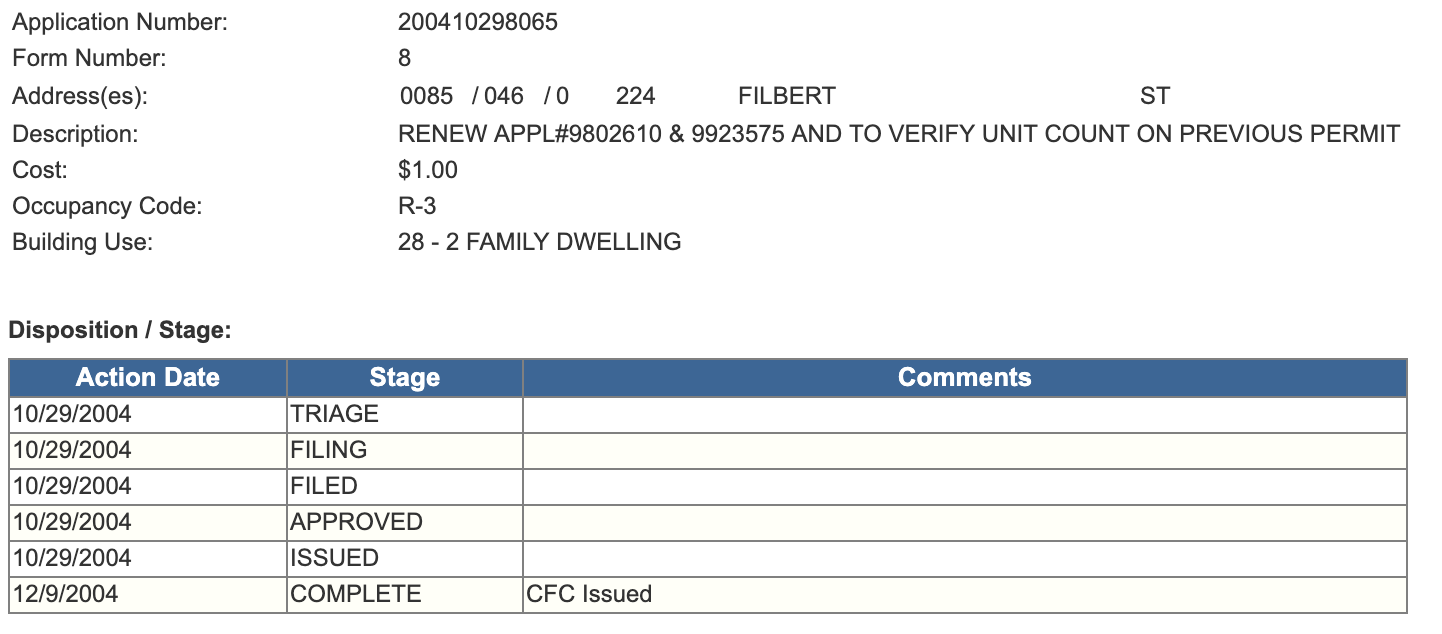 Ironically, the permit page lists the building very clearly as a “2 FAMILY DWELLING”.
Ironically, the permit page lists the building very clearly as a “2 FAMILY DWELLING”.


{kind=link}
{kind=link}
{kind=link}
{kind=link}